| Target Video | Single View Inversion | Ours |
Abstract
Current 3D GAN inversion methods for human heads typically use only one single frontal image to reconstruct the whole 3D head model. This leaves out meaningful information when multi-view data or dynamic videos are available. Our method builds on existing state-of-the-art 3D GAN inversion techniques to allow for consistent and simultaneous inversion of multiple views of the same subject. We employ a multi-latent extension to handle inconsistencies present in dynamic face videos to re-synthesize consistent 3D representations from the sequence. As our method uses additional information about the target subject, we observe significant enhancements in both geometric accuracy and image quality, particularly when rendering from wide viewing angles. Moreover, we demonstrate the editability of our inverted 3D renderings, which distinguishes them from NeRF-based scene reconstructions.
Links

Overview
1. We introduce a multi-view 3D GAN inversion method that uses multiple views simultaneously for reconstructing a 3D face from a shot video sequence. Further, we optimize multiple latent vectors at once to compensate for inconsistencies during the target video.
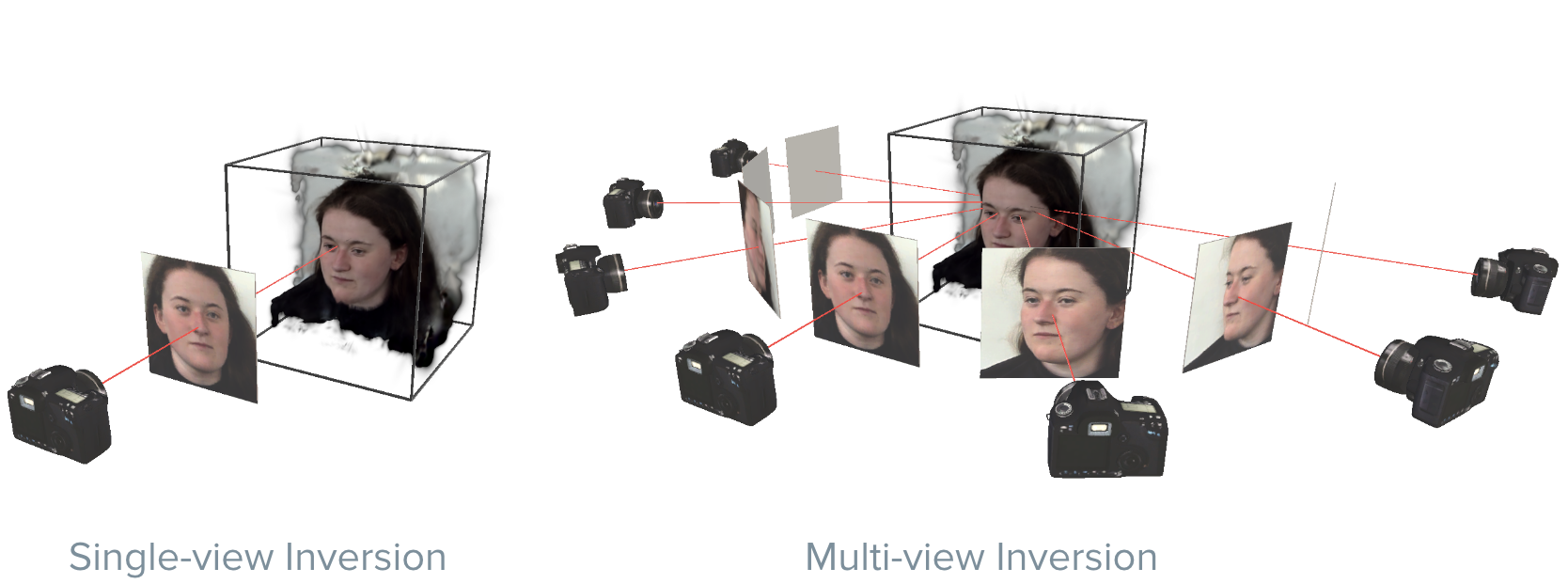
2. As current 3D inversion methods all rely on a single input image, our multi-view method especially improves the rendering quality at steep viewing angles.

3. In contrast to NeRF-based scene reconstruction methods, our method allows for editing of the inverted images.

Citation
@inproceedings{Barthel2024,
title = {Multi-View Inversion for 3D-aware Generative Adversarial Networks},
url = {http://dx.doi.org/10.5220/0012371000003660},
DOI = {10.5220/0012371000003660},
booktitle = {Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications},
publisher = {SCITEPRESS - Science and Technology Publications},
author = {Barthel, Florian and Hilsmann, Anna and Eisert, Peter},
year = {2024}License
The structure of this page is taken and modified from nvlabs.github.io/eg3d which was published under the Creative Commons CC BY-NC 4.0 license .
Acknowledgments
This work has partly been funded by the German Research Foundation (project 3DIL, grant no.~502864329) and the German Federal Ministry of Education and Research (project VoluProf, grant no.~16SV8705).